2026 · RTL designer
GeMM-64 — A Highly Efficient Matrix-Multiply Accelerator
A 64-PE matrix-multiply accelerator written in SystemVerilog. Three tile-mapping modes, dual-FSM pipelining, and a roofline telling the system is near maxed out

Overview
GeMM-64 is a purely digital design project. A fast hardware accelerator for dense matrix multiplication, built from scratch in SystemVerilog. The aim wasn’t mere correctness, I strived for near optimal hardware usage across multiple problem dimensionalities.
Microarchitecture
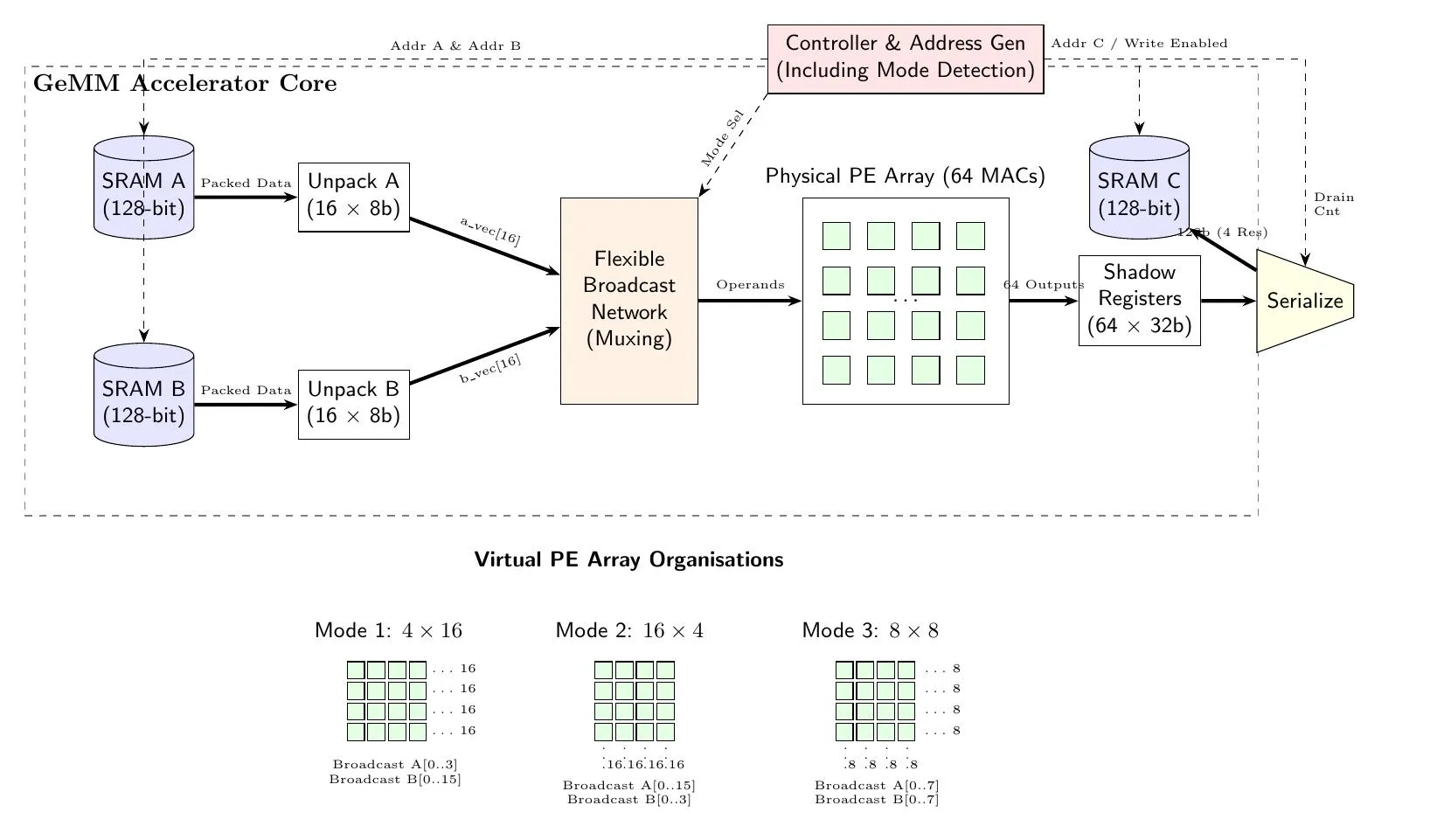
- 64 Processing Elements (PEs) arranged in a 8x8 array fed by a dynamic broadcasting network. Each PE is a multiply-accumulate (MAC) unit with pipelined shadow registers so a tile’s results can drain while the next tile’s inputs are already being consumed, inherently removing a bus-constrained SRAM bottleneck.
- Dual-FSM control. Two FSMs work concurrently. The write-back stage overlaps with the next tile’s computation. That cuts ~35–45% MAC off cycle counts versus a serialized baseline, drastically increasing performance.
- Three tile-mapping modes. Problem definitions stated three different sized matrix-matrix workloads. Smartly packed matrix elements arrive at the MAC without increased latency.
- Memory layout. Multi-step tiling matched to a 128-bit-wide SRAM read; arithmetic intensity (AI) is fine-tuned to keep the array fed without burning bandwidth on partial loads.
Highlights
- Roofline-driven. Performance characterized as ops/cycle vs. arithmetic intensity; the design lands close to the compute roof for the tested workloads, not the bandwidth roof.
- Pipelined Shadow Registers. Adding an output pipelined register is well worth the area cost, as this allows a near perfect MAC utilization across workloads.
Status
Final report submitted in May 2026 with a 19/20 received grade.