2026 · ML & simulation engineer (team of 4)
A Gesture to Learn — Synthetic Ultrasound for Hand-Pose Recognition
An end-to-end pipeline that turns public forearm MRI scans into synthetic ultrasound and trains a 1D CNN to recognize hand poses. Built to sidestep the dataset scarcity that bottlenecks wristband gesture interfaces — no physical transducer required.

Overview
Wristband gesture recognition needs large, expensive ultrasound datasets that nobody publishes. This project removes this bottleneck by generating the data synthetically: take public forearm MRI scans, segment the tissue, simulate what an ultrasound transducer would hear, and train a classifier on the result. The whole thing lets you evaluate a sensor layout before a single physical transducer has been built.
The pipeline recognizes six static forearm poses across four subjects, and is evaluated under a Leave-One-Subject-Out (LOSO) protocol. This is the honest test, where the model never sees the subject it’s scored on.
Architecture
Three decoupled stages, each independently validated before moving forward.
- Anatomy → tissue maps. 2D forearm cross-sections sliced from MRI volumes, manually segmented in ITK-SNAP into six classes (bone, muscle, tendon, fat, joint, water-like background). MONAI augmentation — rotations, zoom, elastic deformation with nearest-neighbor interpolation to keep labels integer-valued — expands ~68 manual slices into ~2000 samples per subject.
- Tissue maps → ultrasound. Each tissue class is mapped to acoustic properties (sound speed, density, power-law attenuation) and pushed through the k-Wave solver on GPU. Three transducer geometries simulated: an 8-element linear array, a 32-element clustered array, and a compact smartwatch-like layout. Gaussian-modulated 5 MHz pulse with Hann apodization; PML boundaries; grid sized dynamically to the anatomy.
- Ultrasound → pose. Hilbert envelopes, median filtering, and aggressive temporal downsampling feed a custom 1D CNN. Three convolutional blocks (64 → 128 → 256, kernels 15/9/5) with adaptive average pooling and a six-class softmax — ~248k parameters.
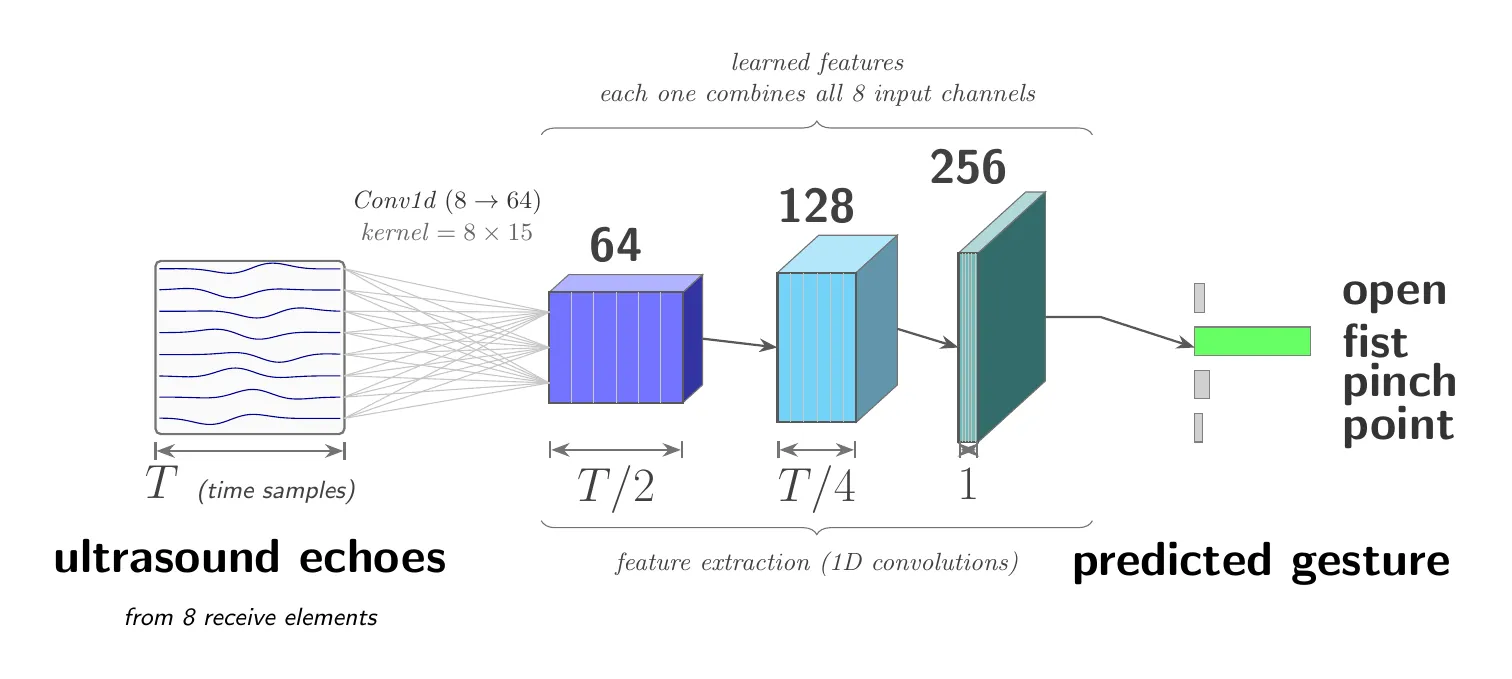
Highlights
- Translation-invariant by design. The adaptive average pooling layer collapses the time axis entirely, forcing the network to read the shape of an echo burst rather than its absolute arrival time. Since different forearms place the same tissue boundary at different depths, this is the single most important choice for cross-subject generalization.
- Architecture search that knew when to stop. Swept seven designs from 12k to 465k parameters. The three-block model lifted LOSO test accuracy to 0.422 — a ~49% relative gain over the original two-block baseline (0.283). Bigger models raised validation accuracy but not test accuracy: textbook memorization of the three training subjects, caught before it could mislead.
- Baselines that fail honestly. LogReg and MLP hit ~1.0 training accuracy and collapse to chance (~0.17) under LOSO — clean evidence that pose information lives in localized echo structure, not global amplitude. The CNN is the only architecture that generalizes across subjects.
- A near-deployable result. Restricting to the four most anatomically distinct poses pushes LOSO test accuracy to ~0.80 against a 0.25 chance line — enough for broad gesture categories on a real wearable.
- Diagnosing the ceiling, not hiding it. A persistent ~0.30 validation–test gap traced to inter-subject domain shift rather than overfitting — confirmed by re-running the same pipeline on real wristband data (collapses to chance) and against same-subject splits (jumps to ~0.73). The binding constraint is the four-subject cohort, not the model.
Status
Final report submitted for the P&O Nanoscience course (KU Leuven · imec), 2025–2026. The headline takeaway: synthetic ultrasound is a usable training signal, but broader anatomical coverage (e.g. more subjects) is required for subject-independent deployment.